Kindle notes
I was looking at an effective way to organize my Kindle highlights. I started looking at parsing the Kindle’s My Clippings.txt file. However I had not much luck with existing PyPi modules and it is a bit cumbersome to always have to manually copy it via USB cable.
Starting point: Cloud + Bookcision
Then I found a much better starting point: https://kindle.amazon.com = cloud. OK, this only works for Kindle purchased books, but using Amazon’s Whispersync really makes this convenient. Also, the Kindle site lets you filter / adjust your highlights and notes before exporting.
For export I use the nice Bookcision JS bookmarklet which – when used in Chrome – gives you the ability to dowload the highlights JSON format.
JSON => HTML
I wrote a script to convert the Bookcision JSON download into a static HTML page (for blog use, inspired by Sivers).
Code is here.
Some things to note:
-
Use json.loads(fh) to convert JSON into dict:
def load_json(json_file): with open(json_file) as f: return json.loads(f.read()) -
Template strings: in templates.py PAGE defines the whole page, I use embedded CSS to make this a standalone solution. QUOTE defines a list item (highlight). Variables are defined with $ so: $title, $author, etc. In the main script I can substitute these variable placeholders with a dict:
def get_highlights(highlights): for hl in highlights: yield QUOTE.safe_substitute({ 'text' : hl['text'], 'note' : ' / note: ' + hl['note'] if hl['note'] else '', 'url' : hl['location']['url'], 'location': hl['location']['value'], })
Note the ‘yield’ makes get_highlights() a generator. If this is new, check out this SO thread about Iterables -> Generators -> Yield [1]
-
Use list() to consume all generator’s values in one go:
highlights = get_highlights(content['highlights']) ... ... 'content': '\n'.join(list(highlights)), -
You can give the script one or more JSON files simply by using a slice on sys.argv:
for json_file in sys.argv[1:]: ... -
So you can batch process JSON downloads:
$ ls *json anything-you-want.json arnold.json choose-yourself.json the-circle.json $ python kindle_json2html.py *json anything-you-want.html created arnold.html created choose-yourself.html created the-circle.html created
Example
Here is what an output looks like:
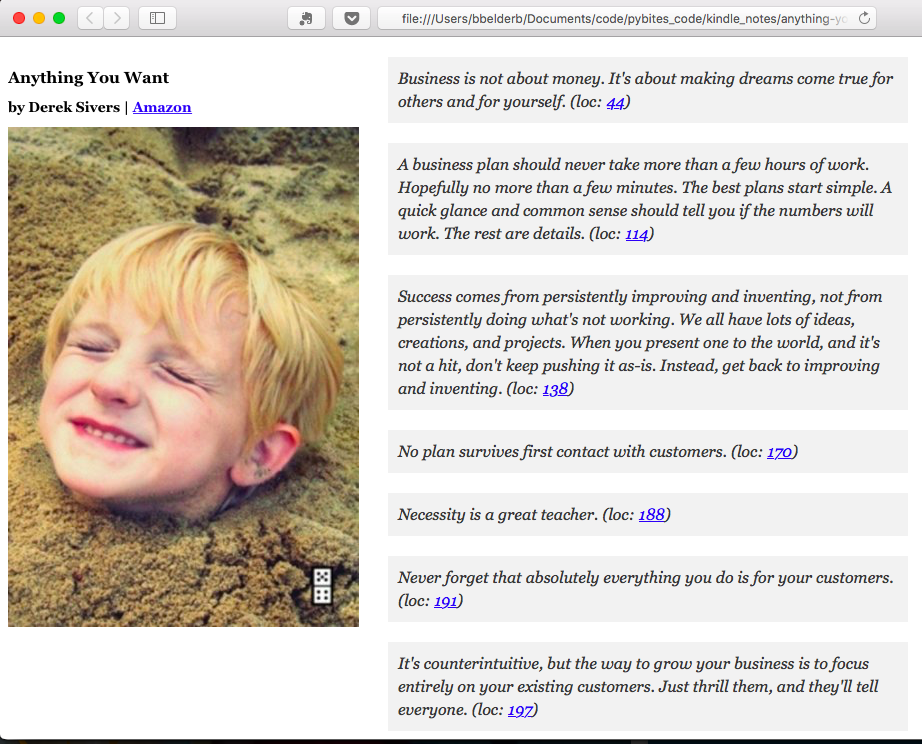
As the HTML contains everything you can just copy it to your blog, example.
Keep Calm and Code in Python!
— Bob
[1] Generators save memory by not materializing the values of an iterable in memory = better performance. Here we don’t really need that, yet I stil find the yield syntax more elegant (it’s shorter) than building and returning a local collection (list).