I have learned a lot over the past 2.5 years of my Python journey. What started out as a hobby during COVID-19 lock downs in 2020, has now become a major component of my professional workload. This article is designed to highlight the importance of the iterative process: write some code -> learn new stuff -> review some code -> refactor. I will share some code I wrote in April and May of 2020 (approximately two months into learning Python), my thought process at the time, how I decided to refactor it, and finally a performance comparison.
One crucial factor that I will not mention in this particular article is testing. Yes, I should have had some tests to run against my refactored code to ensure I was not wandering off course. I did manually confirm that the refactored code produced a similar result to the original code. There are slight differences due to inaccuracies in the original which are discussed later. However, this code was made to be used by only me and not in production. I mean, when I first wrote the code, I didn’t even know what tests were. Instead, I will focus design decisions and the surprising, if not incidental, performance impacts. All of the code shown below is available in a Github repo.
Background
I recently earned a master’s degree in Curriculum and Instruction. One class in the program was centered on a text that inspired some strong opinions. I interpreted the text as blaming educators and didn’t appreciate it at all. So the thesis of one of my papers (Specious Solutions) focused on dismantling their argument on proportional representation (PR). In schools, at least here in California, US, we have different categories for students. If a student needs extra academic or emotional support or have some kind of disability, they can receive special education services and are subsequently categorized as Special Education (SPED). If students come from poor families as indexed by federal standards they are categorized as low Socioeconomic Status (SES). In case you didn’t read the linked paper, here is part of the argument that got me so worked up:
Because proportional representation anchors the equity audit (as discussed above), the equity audit form requires that data collection include fractions along with percentages to be able to measure proportional representation. For example, of 100 students labeled with disabilities, if 70 of these students receive free and reduced-priced lunch, then the fraction for this data is 70/100 and the percent is 70%. This data can then be compared to the percent of students in the school who are receiving free and reduced-price lunch, which in this example is 210 students out of 600 (210/600 = 35%). Thus, in this example, at this school, we know that students from low-income homes are twice as likely to be labeled for special education, and thus are over-represented in special education. Proportional representation of students from low-income homes in special education should be 35% or less.
Without getting too far into the weeds (if you enjoy getting into the weeds, go read the paper), their argument assumed that SPED and low SES are independent and randomly distributed across the population. But even if that were the case—I cite evidence in the paper that is most likely not the case—I was not convinced that PR would be likely to occur naturally. Given that past me had been learning Python, for like two months, I decided to create a simulation.
Original Sin Code
My idea was to simulate a school by randomly labeling students as SPED or Low SES using the given probabilities from the text. The program would count how many students were labeled as SPED, low SES, or both and calculate the portion of low SES students overall and low SES students in SPED. If the portions matched precisely, the school would have PR. It would repeat this process for a large number of trials and see how often it actually happened.
One more detail before we get to the code, though the text claimed that PR for low SES students in SPED should be 35% or less, that was actually the first flaw of their argument. Since the portions of students with various labels must add up to 100% of the student body, if low SES students are under-represented in SPED that must be accompanied by an over-representation of students with another label. Thus, low SES being under-represented in SPED would lead to the same inequity they are decrying. Still, I cut them some slack and also included schools that were within 2% of the upper limit they set.
I wasn’t sure how to accomplish the simulation, but I did know that I could generate random numbers with Python. So I started with googling (sure I use duck duck go, but doesn’t everyone just call it googling?) something along the lines of “choosing random numbers based on a probability”. Somewhere across the internet I stumbled upon numpy.random.binomial. This returned either 0 or 1 based on the probability provided as a parameter. I ran this twice with the probabilities for sped and low SES respectively, converted the integers to strings so I could concatenated them. Then converting them back to integers resulted in 10 representing a student being labeled as SPED, 1 represented a student being labeled as low SES, and 11 was labeled both. (Why didn’t I just compare the strings? I’m not sure. Maybe at the time I thought I could only compare numerical values? I really don’t remember.) I must warn you, the code you are about to see is rough. Here is my original script in all its glory:
import numpy as np
import random
n = 1
p_sped = (1/6)
p_lowin = (7/20)
runs = 10000
pop = 600
PR_exact = 0
PR_twoper = 0
for i in range(runs):
sped = 0
lowin = 0
both = 0
sample_school = []
for s in range(pop):
student = str(np.random.binomial(n,p_sped)) + str(np.random.binomial(n,p_lowin))
if int(student) == 10:
sped += 1
elif int(student) == 1:
lowin += 1
elif int(student) == 11:
both += 1
sample_school.append(student)
per_lowsped = both/(sped + both)
per_lowpop = (lowin+both)/(pop)
if 0<(per_lowsped-per_lowpop)<= 0.02:
PR_twoper += 1
elif per_lowsped==per_lowpop:
PR_exact +=1
prob_PR_exact = (PR_exact/runs)*100
prob_PR_twoper = (PR_twoper/runs)*100
print('The probability of having exact proportional representation in ' +str(runs) + ' trials is: '
+ str(prob_PR_exact) + '%')
print('The probability of having proportional representation within 2% in ' +str(runs) + ' trials is: '
+ str(prob_PR_twoper) + '%')
I know, I know… Let’s identify some issues:
- Formatting: inconsistent spacing and sporadic, unnecessary parentheses. I clearly had not yet heard of black.
- Naming conventions: objectively terrible. C’mon man, I wrote this and still struggled with
PR_twoper. I had forgotten what many of my variable names stood for until I went back and read the original paper. - Unused imports: why was I importing random? I didn’t even use it!
- Inefficient: I am using numpy (which is supposed to be super fast!), but then converting to a string, because I needed two labels, and then converting it back to an integer for the conditionals. I also created a sample school list and appended students to it, but then I never used it. What?!?
- Inaccurate: I wasn’t aware how inaccurate floats could be I didn’t include any kind of rounding. Furthermore, during the refactoring process I realized I should have included the exact proportional representation in the “within 2%” calculation as well. This is a small difference and doesn’t change the analysis of the paper, but still important to address.
If for some reason—unfathomable to the average human mind—you want to work with the original code it is available in the repo.
Refactoring
In this section I will describe my thought process in refactoring the original code into something more readable. My goal is to abstract chunks of code that are responsible for specific behavior into functions. I did not try to come up with all the functions at once. The final code that I am sharing with you happened incrementally.
The first thing I did was run the code against black. While this move alone made it easier to read, I knew that wasn’t the biggest problem (don’t want to miss the gorilla). Next up, I knew that I needed better variable names. Ultimately, I decided to let that happen organically as I created the functions. As an added bonus, abstracting behavior into functions allowed me add docstrings and type hints. This way if I, or anyone else, eventually review this code again, I will know what past me was thinking.
Creating a School
The first structural issue that jumped out at me was the nested for loops. Starting with the inner loop, I tried to describe in simple, plain language what was happening. I am creating a school and counting the numbers of students with each label. This lead to the helper function _create_trial_school().
def _create_trial_school(
population: int, prob_sped: float, prob_low_ses: float
) -> Counter:
"""Creates a counter of students with one of four possible labels: 'sped low',
'sped high', 'gen_ed low' 'gen_ed high'.
:population: int The number of students in the school.
:prob_sped: float The probability that a student is labeled as sped.
:prob_low_ses: float The probability that a student labeled as low ses.
:returns: Counter The number of students with each label.
"""
school = Counter()
for s in range(population):
student = (
choices(
population=["sped ", "gen_ed "],
weights=[prob_sped, 1 - prob_sped],
)[0]
+ choices(
population=["low", "high"],
weights=[prob_low_ses, 1 - prob_low_ses],
)[0]
)
school.update([student])
return schoolCurrent knows that counters exist and are awesome. So I used a counter object instead of counting manually with if/else statements. Next, I needed to address that awful use of numpy.random.binomial(). Utilizing my favorite tool ever—googling until I find an answer—I settled on choices() from the built-in random module.
Using choices() lets me assign a probability and choose from a list of strings instead of generating integers. Meaning, I can get rid of the embarrassing int -> str -> int conversions. (Honestly, I would appreciate it if we never spoke of that again. Thanks in advance.) Since I was choosing from a sequence of strings, I needed to create the compliments of my labels as well. The compliment of SPED is general education (gen_ed) and the compliment of low SES is high SES (high). (Technically, the compliment of low SES is both mid and high SES combined, but for simplicity I with when with the dichotomy of low and high.) I concatenated the labels resulting in four possibilities: “sped low”, “sped high”, “gen_ed low”, “gen_ed high”. The school counter is updated with each student and returned by the function. The difference between the original and refactored code is shown below. I am using the ellipse (…) to indicate that there is other code not being displayed here.
# This original code
...
sped = 0
lowin = 0
both = 0
sample_school = []
for s in range(pop):
student = str(np.random.binomial(n,p_sped)) + str(np.random.binomial(n,p_lowin))
if int(student) == 10:
sped += 1
elif int(student) == 1:
lowin += 1
elif int(student) == 11:
both += 1
sample_school.append(student)
...
# Becomes this refactored code
...
school = _create_trial_school(population, prob_sped, prob_low_ses)
...In the overall flow of the simulation, I was able to replace 13 lines of code with one line that calls a function. More importantly, the logic encompassed by the original 13 lines has been abstracted to a name that clearly describes it.
Counting Proportional Representation
Up next, another counter! I identified a specific behavior and described it in plain language: I am counting how many of my newly created trial schools actually have proportional representation. This time however, I needed this counter to persist across schools. My solution was to create a Counter() object outside of the first for loop of my original code and then create a helper function _update_pr_counts() that updates the counter after each trial school as been created.
def _update_pr_counts(
pr_counter: Counter,
percent_low_ses_overall: float,
percent_low_ses_in_sped: float,
) -> None:
"""Updates the number of schools that have proportional representation.
:pr_counter: Counter The proportional representation counter to be updated.
:percent_low_ses_overall: float The percentage of students at the school who are
labeled low income.
:percent_low_ses_in_sped: float The percentage of students who are labeled both as
low income and sped.
:returns: Counter The proportional representation counter updated if the school has
proportional representation.
"""
pr_delta = percent_low_ses_overall - percent_low_ses_in_sped
if pr_delta == 0:
pr_counter.update(["exact"])
if 0 <= pr_delta <= 0.02:
pr_counter.update(["within range"])
return pr_counterThis fixes both the inaccuracies of rounding error and not including exact PR in the 2% range. It also provides more descriptive variable names. Having _create_trial_school() return a counter slightly changes how I had to count and calculate the portion of low SES students in SPED, and low SES overall. I split it into two parts. First, calculate the counts and then pass the portions directly as parameters of _update_pr_counts().
# This original code
...
for i in range(runs):
...
per_lowsped = both / (sped + both)
per_lowpop = (lowin + both) / (pop)
if 0 < (per_lowsped - per_lowpop) <= 0.02:
PR_twoper += 1
elif per_lowsped == per_lowpop:
PR_exact += 1
...
# Becomes this refactored code
...
proportional_representation = Counter()
for _ in range(trials):
...
count_sped = school["sped low"] + school["sped high"]
count_low_ses = school["sped low"] + school["gen_ed low"]
proportional_representation = _update_pr_counts(
proportional_representation,
percent_low_ses_overall=round(count_low_ses / population, 3),
percent_low_ses_in_sped=round(school["sped low"] / count_sped, 3),
)
...Calculating and Printing the Results
The last item I needed to address is calculating the results. I decided to go with a dictionary comprehension to convert the counts to percents. Apparently, past me had not yet learned about f-strings, so I cleaned up the print statements utilizing f-strings as well. Finally, you’ll notice a little if statement. This is a flag that allows me to decide if I want to print the results or not. This was only added later after I decided to compare the performance. When the number of trials is small, it is possible to have no schools with PR so I used the dict method .get() to provide a default value.
# This original code
...
prob_PR_exact = (PR_exact/runs)*100
prob_PR_twoper = (PR_twoper/runs)*100
print('The probability of having exact proportional representation in ' +str(runs) + ' trials is: '
+ str(prob_PR_exact) + '%')
print('The probability of having proportional representation within 2% in ' +str(runs) + ' trials is: '
+ str(prob_PR_twoper) + '%')
...
# Becomes this refactored code
...
results = {
pr: round(count / trials * 100, 2)
for pr, count in proportional_representation.items()
}
if print_results:
print(
f"The probability of having exact proportional representation in {trials:,} trials is: {results.get('exact', 0.0)}%"
)
print(
f"The probability of being within 2% in {trials:,} trials is: {results.get('within range', 0.0)}%"
)
...I decided that I should abstract the entire simulation into a function called run_trials(). This allows me to run the trials utilizing the if __name__ == “__main__”: idiom (again something that past me had no clue even existed). I also recently learned what it meant to set the random seed after an interaction with Reuven Lerner on Twitter. Basically it will generate the same set of pseudo-random numbers so the results of the simulation will be consistent. I believe the resulting refactoring makes it easier to follow what is happening in the simulation, is much better documented, and makes it simpler to run simulations with different parameters.
def run_trials(
trials: int,
population: int,
prob_sped: float,
prob_low_ses: float,
print_results: bool = True,
) -> dict[str, float]:
"""Run trials to simulating a school with a given probabilities of students being
labeled sped and low ses.
:trials: int The number of trials to run.
:population: int The number of students at the school.
:prob_sped: float The probability that a student is labeled as sped.
:prob_low_ses: float The probability that a student is labeled as low ses.
:returns: dict Contains the percentages of schools that have proportional
representation across all trials.
"""
proportional_representation = Counter()
for _ in range(trials):
school = _create_trial_school(population, prob_sped, prob_low_ses)
count_sped = school["sped low"] + school["sped high"]
count_low_ses = school["sped low"] + school["gen_ed low"]
proportional_representation = _update_pr_counts(
proportional_representation,
percent_low_ses_overall=round(count_low_ses / population, 3),
percent_low_ses_in_sped=round(school["sped low"] / count_sped, 3),
)
results = {
pr: round(count / trials * 100, 2)
for pr, count in proportional_representation.items()
}
if print_results:
print(
f"The probability of having exact proportional representation in {trials:,} trials is: {results.get('exact', 0.0)}%"
)
print(
f"The probability of being within 2% in {trials:,} trials is: {results.get('within range', 0.0)}%"
)
return results
if __name__ == "__main__":
seed(1)
trials = 10000
results = run_trials(trials, 600, 0.166, 0.35)The entirety of the refactored code can be found in the Github repo.
Leveling Up
There was still something that bothered me about the refactored code, namely, _create_trial_school(). This next section serves to illustrate the utility of abstracting specific behavior into functions. I can now focus all my mental registers on working within _create_trial_school() and not worry about the rest of the code. Here is the body of the function to refresh your memory:
...
school = Counter()
for s in range(population):
student = (
choices(
population=["sped ", "gen_ed "],
weights=[prob_sped, 1 - prob_sped],
)[0]
+ choices(
population=["low", "high"],
weights=[prob_low_ses, 1 - prob_low_ses],
)[0]
)
school.update([student])
return schoolI didn’t like that choices() returned a list. In the refactored form above I had to retrieve the labels using indexing, then concatenate them together. It would be so much easier if I could just call choices once with the appropriate probabilities for each label. And after doing some more digging (and actually reading the friendly manual), I saw that choices() actually has a k argument and returns “a k sized list of elements chosen from the population with replacement“. That meant I could label the entire student population in one fell swoop. But how to calculate the correct probabilities? I no longer had a coding problem; I had a math problem.
I thought and thought. I wrote some code that resulted in that 200% of low SES being in SPED (I really don’t want to talk about it). I emailed a colleague asking about the probability of independent events. He, very politely, informed me I was COMPLETELY wrong in my assumptions. And then I, begrudgingly, did what I also ask of my students. Draw a picture.
OK, I know that the entire student body is the whole (100%). My problem is two-dimensional: SPED and SES so I need a rectangle with an area of 1. The first dimension contains the probability of being labeled SPED (7/20) and general ed (13/20). The second dimension contains the probability of being labeled low SES (1/6) and high SES (5/6). This leads to the picture:
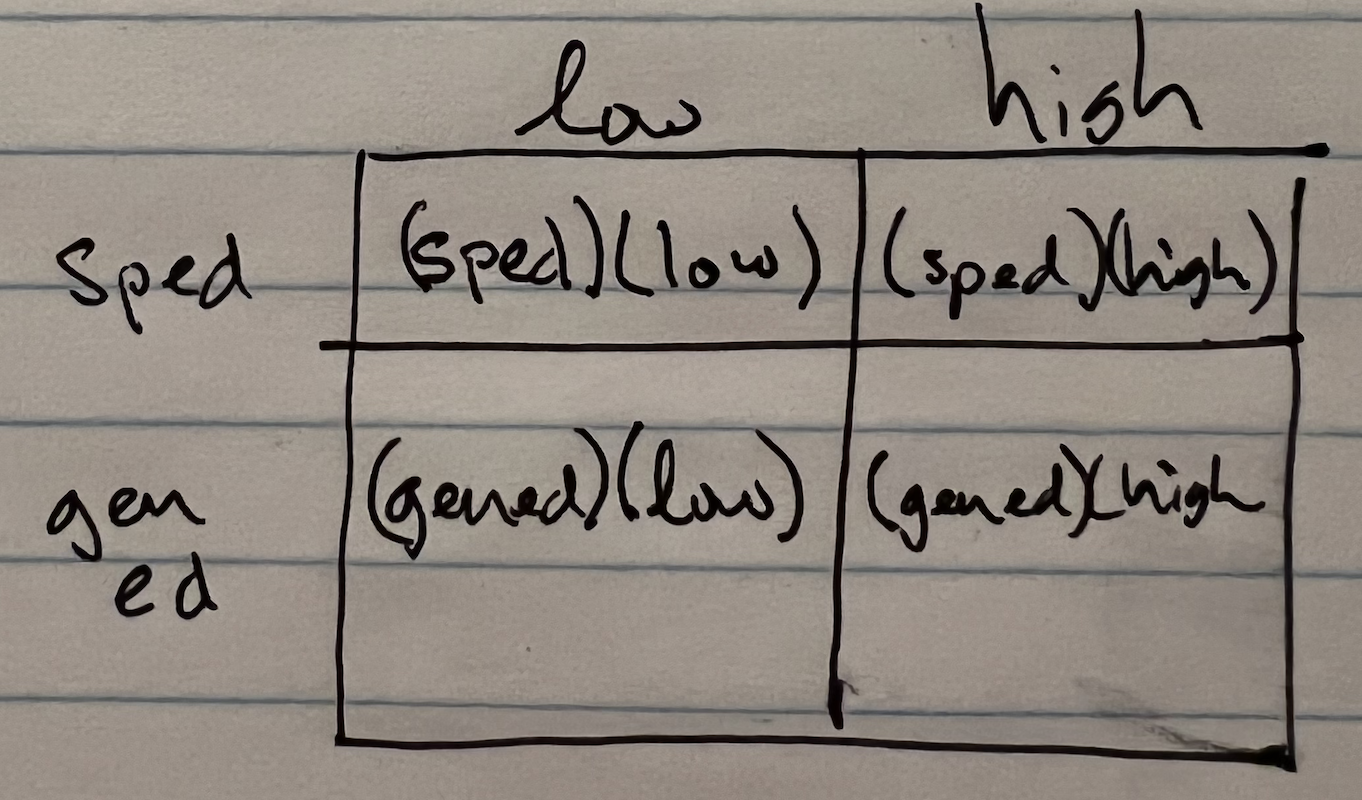
This breaks the original area into quadrants where the dimensions of each quadrant are the four labels I am looking for. Calculating the area of each quadrant yields the probability.

It was so simple. I knew exactly what to do. Refactoring _create_trial_school() again yields:
def _create_trial_school(
population: int, prob_sped: float, prob_low_ses: float
) -> Counter:
...
prob_gen_ed = 1 - prob_sped
prob_high_ses = 1 - prob_low_ses
labels = ("sped low", "sped high", "gen_ed low", "gen_ed high")
probabilities = (
round(prob_sped * prob_low_ses, 3),
round(prob_sped * prob_high_ses, 3),
round(prob_gen_ed * prob_low_ses, 3),
round(prob_gen_ed * prob_high_ses, 3),
)
return Counter(choices(population=labels, weights=probabilities, k=population))I decided to explicitly label the probabilities for the compliments so that when I created the probability tuple later, it was easy to quickly read what was happening. I also made a tuple of the labels instead of concatenating them. This allows me to directly return the counter with choices(), which returns a list of the simulated student body, as the parameter. The improved simulation can also be found in the repo.
Comparing performance
I had done all of this refactoring with the goal of making the code easier to read, understand, and maintain. Performance was an afterthought. But now I was curious. Had all of these changes impacted performance at all? I decided I would time how long each version took to run for some number of trials and then compared the results.
I returned to google, found a timer decorator from Real Python, and modified to fit my needs. In order to easily compare how long each version took to run I needed to move my original code into a function. I copied and pasted it into its own module (original_func.py). I did not change anything that would impact the performance of the original code. But I did run black and gave the function the same arguments as the refactored code. This way I could run all three versions with the same parameters. This allowed me to import the run_trials functions from each module (original_func.py, refactored.py, and improved.py):
from original_func import run_trials as original_run_trials
from refactored import run_trials as refactored_run_trials
from improved import run_trials as improved_run_trialsNext, I created comparison_runner() to run each function while keeping track of the time elapsed and return the results.
def comparison_runner(funcs: dict, trials: int, trial_params: dict) -> dict[float]:
"""Run the three functions with the same number of trials and stats.
:funcs: dict Keys are a printable name, values are the function itself.
:trials: int The number of trials to run.
:trial_params: dict Contains school population and probabilities of labels.
"""
seed(1)
comparison_results = {"Trials": trials}
for i, (func_name, func) in enumerate(funcs.items()):
func = timer(func) # Since functions are imported, I can't use the @timer syntactic sugar
elapsed_time = func(trials, **trial_params)
comparison_results[func_name] = elapsed_time
return comparison_resultsI passed in the functions as a dictionary because the functions are all called run_trials() in their original module. When I tried to print the names, I didn’t know which was which. The dictionary gave me a way to label each function. The trials needed to be passed independently of the other parameters so I could run a different number of trials. And I was able to finally able to make use of the ** unpacking operator (like a badass). comparison_runner() returns a dictionary with the number of trials, function names, and the elapsed time.
I also wanted to display the comparisons. I may be slightly obsessed with rich and this seemed to be the perfect opportunity to create a table.
def display_table(comparison_results: list[dict]) -> None:
"""Display table that compares function performance across a range of trials.
:comparison_results: list A list of results dictionaries from the comparison_runner.
:returns: None
"""
console = Console()
table = Table(title="Comparison Results (in seconds)")
for column in comparison_results[0].keys():
table.add_column(column, justify="center")
for results in comparison_results:
refactored_ratio = round(results["Original"] / results["Refactored"], 1)
improved_ratio = round(results["Original"] / results["Improved"], 1)
last_trial_width = len(str(trial_sets[-1]))
longest_time_width = len(str(comparison_results[-1]["Original"]))
table.add_row(
f"{results['Trials']:{last_trial_width}d}",
f"{results['Original']:0{longest_time_width}.4f}",
f"{results['Refactored']:0{longest_time_width}.4f} [green]({refactored_ratio}x)[/green]",
f"{results['Improved']:0{longest_time_width}.4f} [green]({improved_ratio}x)[/green]",
)
console.print(table)This produced the following table:
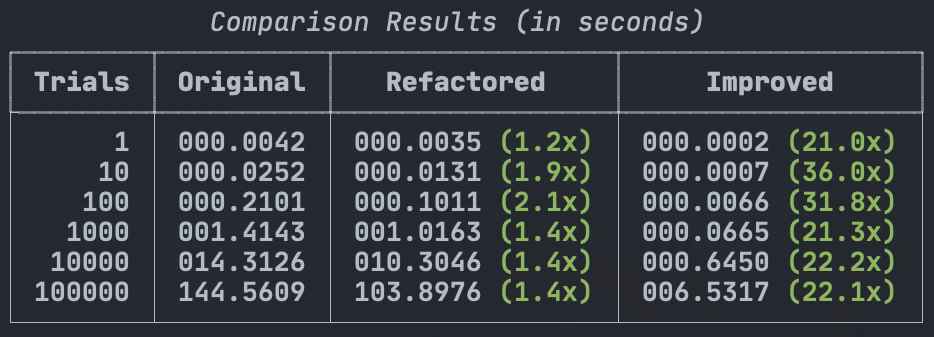
How gorgeous is that? The goal of improving readability resulted in improving performance. By. A. Lot. This is because I am using the tools provided in Python the way the are intended. There are people, more experienced than I am, who have devoted hours and hours to the goal of optimizing these tools. I should honor their work by making use of the tools properly. If you are interested in the entire comparison script is also in the repo.
Moral of the Story
My hope is this story inspires you to write code, keep learning new things, and then apply that learning while keeping in mind the following two axioms:
- Imperfect code that exists > perfect code that doesn’t
- Applying new learning to old code > waiting until you know it all
It would have been impossible for me to write the refactored code back in 2020. I didn’t know about counters, abstracting behavior into functions, what a docstring was, or even that f-strings were a thing. I didn’t know what I didn’t know. I wrote spaghetti code and flung it against the wall to see what would stick.
Today is not much different. I still try things that often don’t work. In fact, my first attempt at refactoring the code I shared with you hit a dead end. I put in hours of work only to realize I was solving the wrong problem. The biggest difference between today and when I first started boils down to two things: knowing how to get help and time in the saddle.
I have found communities like PyBites where I can ask questions when I am stuck. I have been exposed to more vocabulary so I can ask better questions of the community and google. Most importantly, I have written a lot of code with the idea of deliberate practice in mind. To paraphrase the great Excel On Fire, in order to get good, you just need to see a lot of stuff, overall a long period of time. At the time of this writing, I have solved 214 bites on the PyBites Platform. I’ve created lessons for my students. I have written tools that solve problems I’m facing. I am not claiming that it is all good code, but that is part of the process. If your code looks like my original code and you’ve made similar mistakes, that’s okay. It doesn’t matter where you start. Be better tomorrow than you are today.