I have a love of the goodies that you get as part of the developer rewards from submitting Alexa skills to Amazon. Another thing that I also love is the fact that Packt gives away a free book. What I always forget to do is look at what today’s book is and what I didn’t have was a lot of time to meet this month’s deadline for app submission. Why not combine them both?
All of the code can be found on Gitlab.
This post covers the build of the core code. To see the alexa and deployment sections, check out www.rhyspowell.com.
Still to do: tests, logging in and adding the book to my collection.
First steps
Looking at ways of scraping data from websites the option that comes up first is the use of requests and beautifulsoup. Having a little bit of experience with requests it looked as though this would be a fairly easy task, sadly I was wrong. Packt has a level of protection in place that just blocked a simple requests call, despite trying lots of options I just couldn’t get the data.
The next option was to look at using Selenium, something I had done for site testing previously, despite the fact that it was running chrome headless I still kept getting blocked.
A little more searching around and I came across Scrapy. I had previously heard of Scrapy through a talkpython podcast so I thought I would give it a go.
Scrapy
A first look at the documentation is pretty daunting, there’s so much that Scrapy can do for you but the team behind it has put a huge amount of effort into both the docs and getting you up and running very quickly. The tutorial can give you a fully working scraper in less than five minutes and gives a great explanation on how things work, the perfect starting point to butcher the code to my needs.
import scrapy
class PacktSpider(scrapy.Spider):
name = 'packt'
def start_requests(self):
urls = ['https://www.packtpub.com/packt/offers/free-learning']
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
print(response)
name has to be set as the name of the spider, the url was updated to point to the free learning page and set the response to print out:
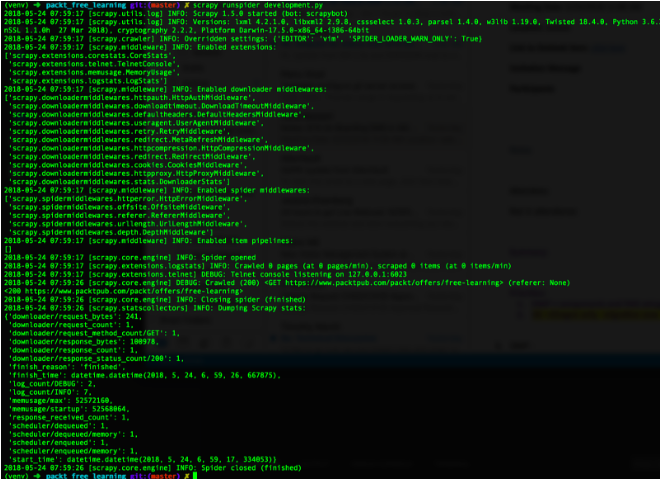
The response was exactly what I was looking for:
2018-05-24 07:59:26 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
<200 https://www.packtpub.com/packt/offers/free-learning>
Scraping the Page
With the ability to finally grab the page data, the next step is to open the page in a browser. I use Chrome, opening the developer tools I can inspect the page html.
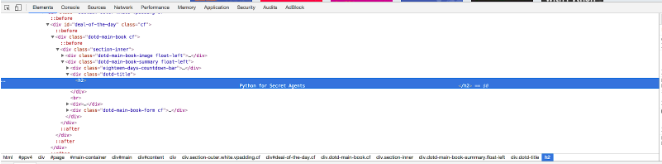
From this it’s easy to see that the piece of information that we are after, the book title, is wrapped with in the class dotd-title. Now the work begins to get the information out of the response data.
Scrapy gives you the choice of three methods of querying the data: css, xpath and re, with css or xpath being the standard methods. Once again the documentation is quite extensive and should be read through to give an idea of what can be done. An additional tool that Scrapy provides is a shell:
(venv) ➜ packt_free_learning git:(master) ✗ scrapy shell 'https://www.packtpub.com/packt/offers/free-learning'
Running the above, processes the spider as it would normally but opens you into a python shell and provides the following objects and information:
2018-05-24 09:20:58 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler
[s] item {}
[s] request
[s] response <200 https://www.packtpub.com/packt/offers/free-learning>
[s] settings
[s] spider
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
Word of warning, when playing in the shell the actual response will be trimmed to a fixed length, if you want to see the full text you need to add the
extract()method at the end of the query.
I will leave you, reader, to play with your own site and work out the selectors.
After much toiling and playing, the fog of how it worked cleared and there was a very simple xpath that gave me what I wanted
response.xpath(
'normalize-space(//div[@class="dotd-title"])'
).extract()[0]
//div[@class=”dotd-title”].extract()
returns
['\n\t\t\t\t\t\t\t\n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\tPython for Secret Agents\t\t\t\t\t\t\t\t\t\t\t\t\t\t
\n\t\t\t\t\t\t']
This shows scrapy returning an array of items that match. In this case, only one. It also pulls everything associated with that div, the css div identifier and all of the white space that is seen on the inspection shown above. The use of xpaths normalize-space
clears the class and all of the whitespace away just leaving the text.
'Python for Secret Agents'
Pushing the data
As this was to be used by Alexa and for the Flash Briefing system it needs to be read as an rss feed in a specific format. As this is a simple feed, one item only, using a library was a bit overkill but as this was always going to run on python 3.6 I could pull f strings out of the bag.
file_text = f''' {{
"uid": "urn:uuid:{uuid.uuid4()}",
"updateDate": "{time.strftime("%Y-%m-%dT%H:%M:%SZ")}",
"titleText": "Packt free learning ebook for today",
"mainText": "{title}.",
"redirectionUrl": "https://www.packtpub.com/packt/offers/free-learning"
}}'''
Using f strings allows you to evaluate code or even previously set variables. If you haven’t yet played with them, I would recommend that you take a look as they can make things so much easier. With the file text set it is fairly simple using the Boto3 library to upload to S3.
s3_client = boto3.client(
's3',
aws_access_key_id=AWS_ACCESS_KEY,
aws_secret_access_key=AWS_SECRET_ACCESS_KEY,
region_name='us-east-1'
)
with open('feed.json', 'w') as f:
f.write(file_text)
# Upload the file to S3
response = s3_client.put_object(
ACL='public-read',
Bucket='packt-free-learning',
Key='feed.json',
Body=file_text,
ContentEncoding='utf-8',
ContentType='application/json',
StorageClass='REDUCED_REDUNDANCY'
)
Error Handling
Happy with the fact I could now grab the data and push it somewhere for Alexa to consume, as my devoted users wouldn’t want to miss their daily update, I needed to make sure that I would be alerted to any issues. At the time I had just listened to a Python Bytes podcast where they had mentioned a package named notifiers and this seemed like a great time to test it out.
For me, doing ops, I live in Slack for most of the day, so that as a platform to send alerts to looked like the best option. The integration required the enabling of the webhooks, a simple app install on the Slack side, then using that app create a specific url to push the data to.
First steps were to define some errors I would likely get that I would be able to see if it was caused by a programming error, the script getting blocked or something on the AWS side.
handle_httpstatus_list = [401, 403, 404, 408, 500, 502, 503, 504]
This sets scrapy to handle any of the http status errors listed allowing me the opportunity to do something with them later in the script.
from notifiers import get_notifier
Sets up our ability to call one of the applications that notifiers supports. Not to tie them together.
404 would give an indication that they have moved the page:
if response.status == 404:
slack.notify(webhook_url=hook, message='404 URL is not good')
402 and 403 might indicate that we were now getting blocked:
elif response.status == 401 or response.status == 403:
slack.notify(
webhook_url=hook,
message='We might have been blocked status '
+ str(response.status)
)
408 and any of the 500s that are being trapped are likely to be a transient error so wait and try again:
else:
slack.notify(
webhook_url=hook,
message='Warning connection type errors. Error number '
+ str(response.status)
+ ' count '
+ str(count)
)
time.sleep(300)
count += 1
if count == 4:
exit(1)
else:
self.start_requests()
It was then a simple case of deploying the app where I wanted it to run. More on that can be found in a post on my blog.
Bonus
A couple of months after the app had been running, a conversation started on PyBites Slack about posting the free book, each day, to the #books channel. I jumped at the chance to offer the app, thinking it would be fun to extend it a bit more.
At the time of offering to help, it had been quite a while since I had looked at the code. I had in mind to use the notifiers module that I had heard of months before, remembering how useful it was.
It was a delight seeing it post to the PyBites Slack channel! Even better, the whole process of adding another notifier took less than 5 minutes!
Keep Calm and Code in Python!