I came across PyBites through a random retweet by some other Pythonista and was intrigued by the challenges Bob and Julian post. Learning cool things by building something always fascinated me so I love and enjoy contributing to the PyBites community through solving random challenges that I find interesting.
Long story short I picked up PyBites Code Challenge 03 and share my solution here.
Background
The aim behind the challenge was to show the top 10 most frequently used tags by PyBites. And similar tags should be listed as well, for example game and games, challenge and challenges, etc. It ended up being even more interesting because I could use the live RSS feed of PyBites which means I could write a script that could monitor commonly used tags over time. I even went one step further by graphically showing them.
Modules Used
- Plotly – a free and Open Source Python graphing library. It has good documentation and is quite easy to use. I used it to come up with the Bar Graph for top 10 tags (see further down).
- FeedParser – a module that makes it easier to parse RSS feeds. Using this you can directly extract title, subtitle, link, entries etc.
Code
The full code for this challenge is here.
The live RSS feed for Pybites returns XML. One possible approach was to parse the XML response and list all the tags being used by PyBites. The other one was to lookout for a module that is used for parsing the RSS feeds. This is how I used feedparser:
blog_feed = feedparser.parse('https://pybit.es/feeds/all.rss.xml'
Now, blog_feed has feed of complete PyBites. But, at a granular level what I really wanted was to retrieve all of the tags. To reach up to tags I had to do two levels of parsing. Going top-bottom. First I looped around all the entries. In particular blog_feed.entries would list details related to all the blog posts by PyBites. Per Blog it would have details like title, title_details, content, tags and so on for all the blogs. Then I looped across all the entries to get the tags. Per blog post I appended all the tags to a list.
def get_tags():
"""
Find all tags in live feed.
Replace dash with whitespace.
"""
tags = []
blog_feed = feedparser.parse('https://pybit.es/feeds/all.rss.xml'
for item in range(len(blog_feed.entries)):
for i in range(len(blog_feed.entries[item].tags)):
word = blog_feed.entries[item].tags[i]['term']
tags.append(word)
return tags
Next step was to get the top 10 tags that are being most commonly used. For this I created a dictionary having tag as the key and count per tag as the corresponding value:
def get_top_tags(tags):
"""
Get the TOP_NUMBER of most common tags.
tags: List of all the tags used by the website.
"""
tag_list = []
D = {}
top_tags = {}
for words in tags:
tag_list.append(words.lower())
key = words.lower()
D[key] = tag_list.count(key)
top_tags = sorted(D.items(),key=operator.itemgetter(1), reverse=True)[:TOP_NUMBER]
return top_tags
The top 10 tags were getting retrieved but similarity had to be calculated as well. SequenceMatcher came in handy for this. Based on the input words it returns a value that shows how similar the two words are. Given the threshold was 0.85, anything above this value was considered similar.
def get_similarities(tags):
"""
Find set of tags pairs with similarity ratio of > SIMILAR.
Argument:
tags: List of all the tags used by the website.
"""
D={}
for word in tags:
word=word.replace(' ','').lower()
for words in tags:
words=words.replace(' ','').lower()
value = SequenceMatcher(None, word, words).ratio()
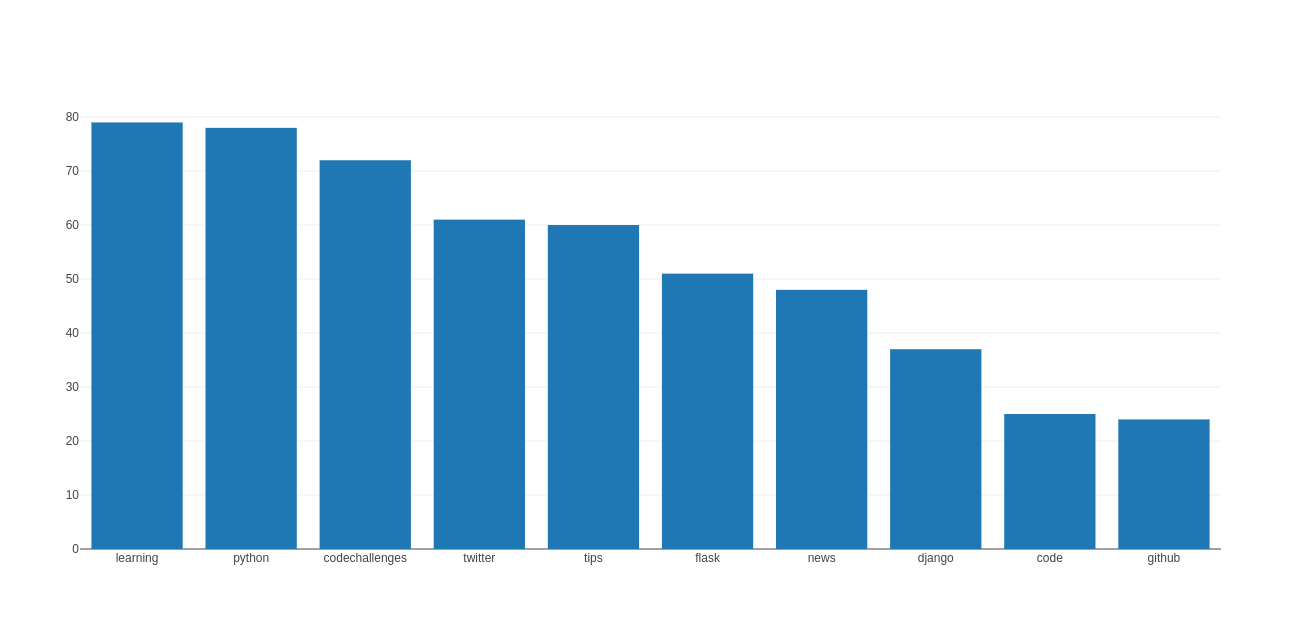
if SIMILARLast but not least, visualization. All I aimed for was to come up with a bar graph that at any point in time shows me the most commonly used tags. To meet this requirement I used Plotly. The crisp documentation helped me a lot. On the x-axis I mentioned the tags being used. And y-axis showed the counts of each tag.
def visualizations(top_tags):
'''
Data visualization using Bar Graph.
Argument:
top_tags: List containing tuples.
And tuple have tag and count respectively.
x axis - tags
y axis - counts
'''
tags=[]
counts=[]
for tag,count in top_tags:
tags.append(tag)
counts.append(count)
data=[go.Bar(
x=tags,
y=counts)]
py.plot(data, filename='basic-visualization')
The top 10 tags at the time I wrote my script:
Learning
- Parsing of RSS Feeds, their utility and scope, and how you can use
feedparserto parse them. - Making a basic visualisation using
plotly. - Calculate similarity between 2 words using the builtin
difflibmodule.
Conclusion
In a nutshell Python is something I love to code in and talk about. PyBites has given me a platform to code more, solve interesting problems to learn by building things. It is definitely a stepping stone. Thanks PyBites!
Keep Calm and Code in Python!
-- Mridu