Table of Contents
- Cleaning Text Data with Python
- Tokenisation
- Normalising Case
- Remove All Punctuation
- Stop Words
- Spelling and Repeated Characters (Word Standardisation)
- Remove URLs, Email Addresses and Emojis
- Stemming and Lemmatisation
- A Simple Demonstration
Cleaning Text Data with Python
Machine Learning is super powerful if your data is numeric. What do you do, however, if you want to mine text data to discover hidden insights or to predict the sentiment of the text. What, for example, if you wanted to identify a post on a social media site as cyber bullying.
The first concept to be aware of is a Bag of Words. When training a model or classifier to identify documents of different types a bag of words approach is a commonly used, but basic, method to help determine a document’s class. A bag of words is a representation of text as a set of independent words with no relationship to each other. It is called a “bag” of words, because any information about the order or structure of words in the document is discarded. The model is only concerned with whether known words occur in the document, not where in the document. It involves two things:
- A vocabulary of known words.
- A measure of the presence of known words.
Consider the phrases
- “The cat in the hat sat in the window“
- “The dog sat on the hat“
These phrases can be broken down into the following vector representations with a simple measure of the count of the number of times each word appears in the document (phrase):
| Word | the | cat | dog | in | on | hat | sat | window |
|---|---|---|---|---|---|---|---|---|
| Phrase 1 | 3 | 1 | 0 | 2 | 0 | 1 | 1 | 1 |
| Phrase 2 | 2 | 0 | 1 | 0 | 1 | 1 | 1 | 0 |
These two vectors [3, 1, 0, 2, 0, 1, 1, 1] and [2, 0, 1, 0, 1, 1, 1, 0] could now be be used as input into your data mining model.
A more sophisticated way to analyse text is to use a measure called Term Frequency – Inverse Document Frequency (TF-IDF). Term Frequency (TF) is the number of times a word appears in a document. This means that the more times a word appears in a document the larger its value for TF will get. The TF weighting of a word in a document shows its importance within that single document. Inverse Document Frequency (IDF) then shows the importance of a word within the entire collection of documents or corpus. The nature of the IDF value is such that terms which appear in a lot of documents will have a lower score or weight. This means terms that only appear in a single document, or in a small percentage of the documents, will receive a higher score. This higher score makes that word a good discriminator between documents. The TF-IDF weight for a word i in document j is given as:
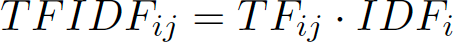
A detailed background and explanation of TF-IDF, including some Python examples, is given here Analyzing Documents with TF-IDF. Suffice it to say that TF-IDF will assign a value to every word in every document you want to analyse and, the higher the TF-IDF value, the more important or predictive the word will typically be.
However, before you can use TF-IDF you need to clean up your text data. But why do we need to clean text, can we not just eat it straight out of the tin? The answer is yes, if you want to, you can use the raw data exactly as you’ve received it, however, cleaning your data will increase the accuracy of your model. This guide is a very basic introduction to some of the approaches used in cleaning text data. Some techniques are simple, some more advanced. For the more advanced concepts, consider their inclusion here as pointers for further personal research.
In the following sections I’m assuming that you have plain text and your text is not embedded in HTML or Markdown or anything like that. If your data is embedded in HTML, for example, you could look at using a package like BeautifulSoup to get access to the raw text before proceeding. You could use Markdown if your text is stored in Markdown.
Tokenisation
Typically the first thing to do is to tokenise the text. This is just a fancy way of saying split the data into individual words that can be processed separately. Tokenisation is also usually as simple as splitting the text on white-space. It’s important to know how you want to represent your text when it is dived into blocks. By this I mean are you tokenising and grouping together all words on a line, in a sentence, all words in a paragraph or all words in a document. The simplest assumption is that each line a file represents a group of tokens but you need to verify this assumption. BTW I said you should do this first, I lied. A lot of the tutorials, sample code on the internet talks about tokenising your text immediately. This then has the downside that some of the simpler clean up tasks, like converting to lowercase and removing punctuation for example, need to be applied to each token and not on the text block as a whole. Something to consider.
Normalising Case
This is just a fancy way of saying convert all your text to lowercase. If using Tf-IDF Hello and hello are two different tokens. This has the side effect of reducing the total size of the vocabulary, or corpus, and some knowledge will be lost such as Apple the company versus eating an apple. In all cases you should consider if each of these actions actually make sense to the text analysis you are performing. If you are not sure, or you want to see the impact of a particular cleaning technique try the before and after text to see which approach gives you a more predictive model. Sometimes, in text mining, there are multiple different ways of achieving one’s goal, and this is not limited to text mining as it is the same for standardisation in normal Machine Learning.
Remove Punctuation
When a bag of words approach, like described above is used, punctuation can be removed as sentence structure and word order is irrelevant when using TF-IDF. Some words of caution though. Punctuation can be vital when doing sentiment analysis or other NLP tasks so understand your requirements. Also, if you are also going to remove URL’s and Email addresses you might want to the do that before removing punctuation characters otherwise they’ll be a bit hard to identify. Another consideration is hashtags which you might want to keep so you may need a rule to remove # unless it is the first character of the token.
Stop Words
Stop Words are the most commonly used words in a language. You could consider them the glue that binds the important words into a sentence together. Sample stop words are I, me, you, is, are, was etc. Removing stop words have the advantage of reducing the size of your corpus and your model will also train faster which is great for tasks like Classification or Spam Filtering. Removing stop words also has the advantage of reducing the noise signal ratio as we don’t want to analyse stop words because they are very unlikely to contribute to the classification task. However, another word or warning. If you are doing sentiment analysis consider these two sentences:
- this movie was not good
- movie good
By removing stop words you’ve changed the sentiment of the sentence. Who said NLP and Text Mining was easy.
Spelling and Repeated Characters (Word Standardisation)
Fixing obvious spelling errors can both increase the predictiveness of your model and speed up processing by reducing the size of your corpora. A good example of this is on Social Media sites when words are either truncated, deliberately misspelt or accentuated by adding unnecessary repeated characters. Consider:
love, luv, lovvvvv, lovvveeee
To an English speaker it’s pretty obvious that the single word that represents all these tokens is love. Standardising your text in this manner has the potential to improve the predictiveness of your model significantly.
Remove URLs, Email Addresses and Emojis
Depending on your modelling requirements you might want to either leave these items in your text or further preprocess them as required. A general approach though is to assume these are not required and should be excluded. Consider if it is worth converting your emojis to text, would this bring extra predictiveness to your model? Regular expressions are the go to solution for removing URLs and email addresses.
Stemming and Lemmatisation
Stemming is a process by which derived or inflected words are reduced to their stem, sometimes also called the base or root. Using the words stemming and stemmed as examples, these are both based on the word stem. Stemming algorithms work by cutting off the end or the beginning of the word, taking into account a list of common prefixes and suffixes that can be found in an inflected word.
Lemmatisation in linguistics, is the process of grouping together the different inflected forms of a word so they can be analysed as a single item. In languages, words can appear in several inflected forms. For example, in English, the verb ‘to walk’ may appear as ‘walk’, ‘walked’, ‘walks’, ‘walking’. The base form, ‘walk’, that one might look up in a dictionary, is called the lemma for the word.
So stemming uses predefined rules to transform the word into a stem whereas lemmatisation uses context and lexical library to derive a lemma. The stem doesn’t always have to be a valid word whereas lemma will always be a valid word because lemma is a dictionary form of a word.
A Simple Demonstration
Let have a look at some simple examples. We start by creating a string with five lines of text:
In [1]: data = """This is the first line
...: This is the 2nd line
...: The third line, this line, has punctuation.
...: THE FORTH LINE I we and you are not wanted
...: I lovveee email fred@flintsones.ie"""
At this point we could split the text into lines and split lines into tokens but first lets covert all the text to lowercase (line 4), remove that email address (line 5) and punctuation (line 6) and then split the string into lines (line 7).
In [2]: import re
In [3]: import string
In [4]: data = data.lower()
In [5]: data = re.sub(r'\S*@\S*\s*', '', data)
In [6]: data = data.translate(str.maketrans('', '', string.punctuation))
In [7]: lines = data.split('\n')
In [8]: lines
Out[8]:
['this is the first line',
'this is the 2nd line',
'the third line this line has punctuation',
'the forth line i we and you are not wanted',
'i lovveee email rocks']
Line 8 now shows the contents of the data variable which is now a list of 5 strings).
Next we’ll tokenise each sentence and remove stop words. Normally you’s use something like NLTK (Natural Language Toolkit) to remove stop words but in this case we’ll just use a list of prepared tokens (words)
In [9]: tokens = [[word for word in line.split() if word not in stop_words] for line in lines]
In [10]: tokens
Out[10]:
[['first', 'line'],
['2nd', 'line'],
['third', 'line', 'line', 'punctuation'],
['forth', 'line', 'wanted'],
['lovveee', 'email', 'rocks']]
The final data cleansing example to look is spell checking and word normalisation. If we look at the list of tokens above you can see that there are two potential misspelling candidates 2nd and lovveee. Rather then fixing them outright, as every text mining scenario is different a possible solution to help identify the misspelt words in your corpus is shown. This would then allow you determine the percentage of words that are misspelt and, after analysis or all misspellings or a sample if the number of tokens is very large, an appropriate substituting algorithm if required.
In [1]: from spellchecker import SpellChecker
In [2]: spell = SpellChecker()
In [3]: misspelled = ['lovve', 'lovee', 'lovvee', 'lovveee', '2nd']
In [4]: for word in misspelled:
...: print(f'{word}: \t{spell.correction(word)} \t{spell.candidates(word)}')
...:
lovve: love {'love'}
lovee: love {'lover', 'love', 'levee', 'loved', 'lovey', 'loves'}
lovvee: love {'lover', 'lovage', 'ovver', 'love', 'levee', ... 'loves', 'loaves'}
lovveee: lovveee {'lovveee'}
2nd: and {'mnd', 'und', 'ond', 'nd', 'cnd', 'ind', 'bnd', 'and', 'hnd', 'end'}
In lines 1 and 2 a Spell Checker is imported and initialised. Line 3 creates a list of misspelt words. Then in line 4 each misspelt word, the corrected word, and possible correction candidate are printed. This is not suggested as an optimised solution but only provided as a suggestion.
Keep calm and code in Python!
— David